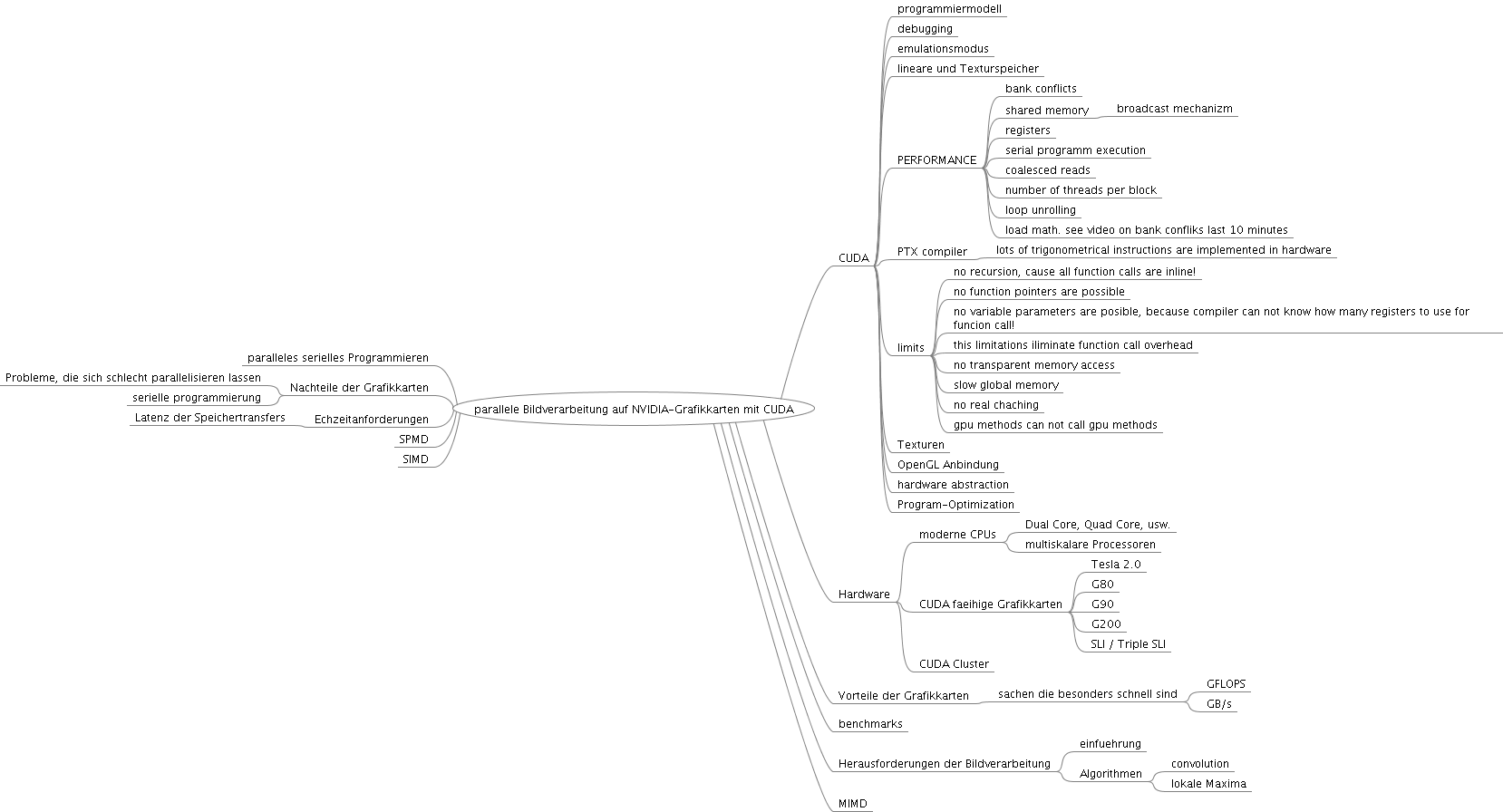
3. Exzerpt
Titel: Efficient Histogram Algorithms for NVIDIA CUDA
Compatible Devices
Quelle: Exzerpt3 (pdf, 207 KB)
Preview:
Die Publikation hat eine klare Gliederung und Diagramme. Es gibt Code-Beispiele.
Fragen:
Die neuste Generation der NVIDIA-Grafikkarten bietet die Möglichkeit des Warp-Votings.
Interessant ist zu untersuchen, ob dieser Mechanismus das Problem einfacher löst.
Des weiteren hat die neueste Generation der Hardware atomare Operationen, die das Problem lösen.
Recite:
CUDA-Architektur bietet keine globale Synchronisationsmechanismen für die parallel laufende Prozesse, des weiteren fehlt die Unterstützung der atomaren nicht unterbrechbaren Operationen. Dies verhindert die effektive Realisierung der Berechnung einer Histogramm aus den gegebenen Daten.
Der Autor schlägt zwei Lösungsansätze vor. Der erste implementierte eine Implementierung der globalen atomaren Operationen in Software. Leider wird diese Methoden sehr langsam, wenn die Daten eine schwache Varianz aufweisen. Für diesen speziellen Fall gibt es eine zweite Methode. Sie lagert alles ins globale Speicher aus. Und zwar, jeder Thread-Block hat einen eigenen Speicherbereich. Aus diesem Grund braucht man am Ende eine parallele Reduktion, die alle Ergebnisse zusammenfasst.
Der Autor glaubt, dass die vorgeschlagenen Methoden das Problem lösen, aber hofft, dass zukünftige Versionen von CUDA alle fehlenden Mechanismen unterstützen, damit das Programmieren dafür leichter wird.
Review:
Diese Publikation beschreibt Umsetzung eines der grundlegenden Algorithmen der Bildverarbeitung. Sie spricht die Probleme der CUDA-Architektur und bietet interessante Lösungsansätze. Die präsentierten Ergebnisse und gute und kompakte Beschreibung der CUDA-Architektur können sich gut in die Ausarbeitung integrieren.
Compatible Devices
Quelle: Exzerpt3 (pdf, 207 KB)
Preview:
Die Publikation hat eine klare Gliederung und Diagramme. Es gibt Code-Beispiele.
Fragen:
- Welche Probleme verhindern eine effiziente Implementierung der Berechnung einer Histogramm?
- Welche Techniken haben effiziente Berechnung ermöglicht ?
-
zu
- Kleine Größe des Shared-Speichers, fehlen der nativen Mechanismen zur globalen und lokalen Synchronisierung, fehlen der nativen atomaren Updates verhindern eine effiziente Implementierung
- Es werden zwei Methoden vorgestellt zur Lösung des Problems. Die erste Methode simuliert atomare Updates. Der Performance von der ersten Methode ist aber schlecht, wenn die Daten eine degradierte Verteilung besitzen. Aus diesem Grund gibt es eine zweite Variante, die diesen Umstand besser löst, in dem Ergebnisse im globalen Speicher abgelegt werden.
Die neuste Generation der NVIDIA-Grafikkarten bietet die Möglichkeit des Warp-Votings.
Interessant ist zu untersuchen, ob dieser Mechanismus das Problem einfacher löst.
Des weiteren hat die neueste Generation der Hardware atomare Operationen, die das Problem lösen.
Recite:
CUDA-Architektur bietet keine globale Synchronisationsmechanismen für die parallel laufende Prozesse, des weiteren fehlt die Unterstützung der atomaren nicht unterbrechbaren Operationen. Dies verhindert die effektive Realisierung der Berechnung einer Histogramm aus den gegebenen Daten.
Der Autor schlägt zwei Lösungsansätze vor. Der erste implementierte eine Implementierung der globalen atomaren Operationen in Software. Leider wird diese Methoden sehr langsam, wenn die Daten eine schwache Varianz aufweisen. Für diesen speziellen Fall gibt es eine zweite Methode. Sie lagert alles ins globale Speicher aus. Und zwar, jeder Thread-Block hat einen eigenen Speicherbereich. Aus diesem Grund braucht man am Ende eine parallele Reduktion, die alle Ergebnisse zusammenfasst.
Der Autor glaubt, dass die vorgeschlagenen Methoden das Problem lösen, aber hofft, dass zukünftige Versionen von CUDA alle fehlenden Mechanismen unterstützen, damit das Programmieren dafür leichter wird.
Review:
Diese Publikation beschreibt Umsetzung eines der grundlegenden Algorithmen der Bildverarbeitung. Sie spricht die Probleme der CUDA-Architektur und bietet interessante Lösungsansätze. Die präsentierten Ergebnisse und gute und kompakte Beschreibung der CUDA-Architektur können sich gut in die Ausarbeitung integrieren.
sleon - 18. Sep, 19:04