Titel:
Scalable Parallel
PROGRAMMING
Quelle:
Exzerpt1 (pdf, 762 KB)
Preview:
Die Publikation sieht wie ein Artikel aus einer Computer-Zeitung.
Es hat viele bunte Diagramme. Gliederung spricht für sich.
Fragen:
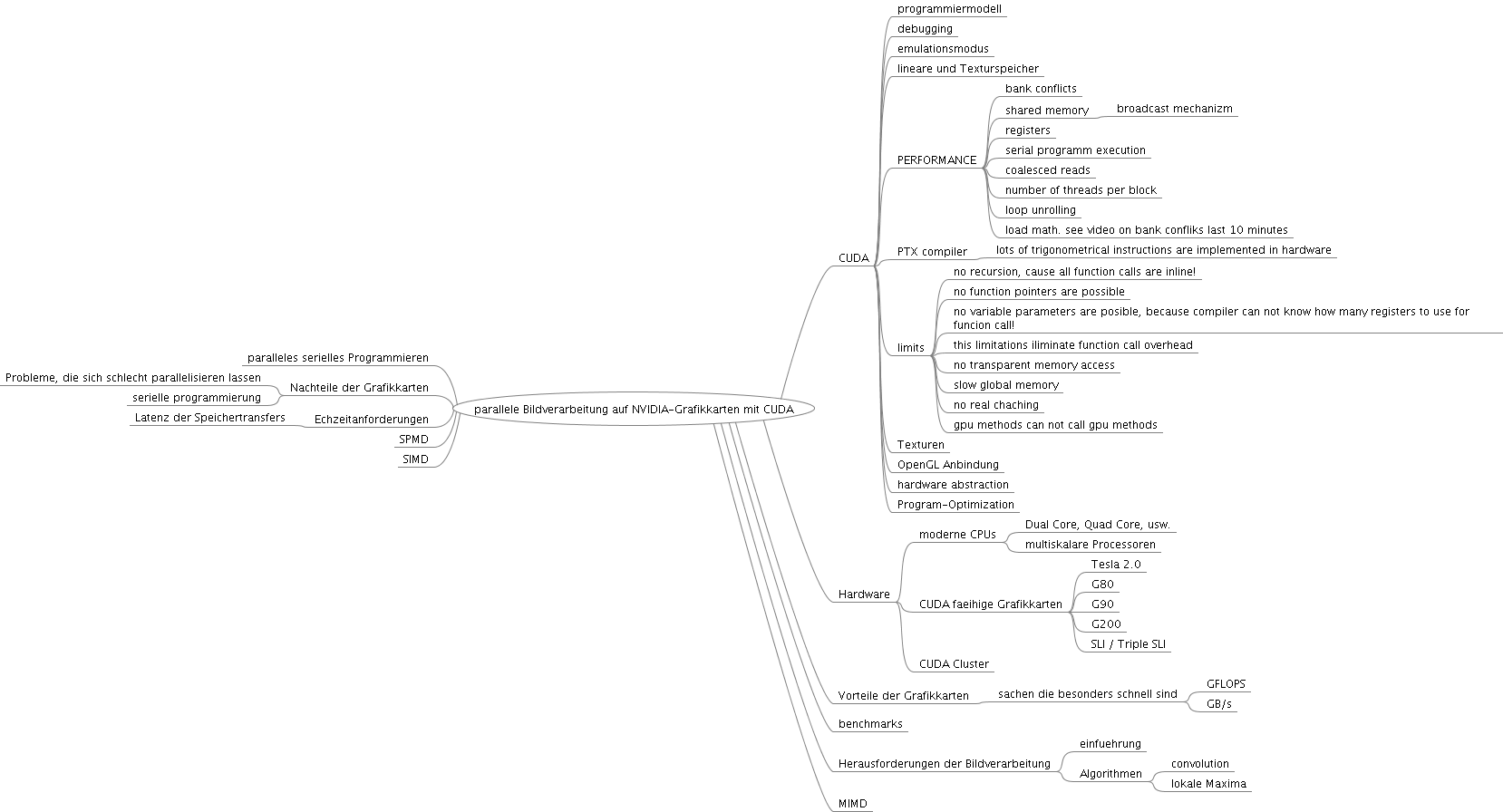
- Was sind die Eigenschaften von der CUDA-Architektur?
- Wie sieht die CUDA-Programmiermodell aus?
- Was sind die Besonderheiten der Programmierung für CUDA
- welche Beispiele werden gemacht?
- wie bewerten die Autoren CUDA?
- In wie weit ist CUDA ein Supercomputer?
- Tesla-Architektur
Read:
zu - Im Artikel werden die wesentlichen Aspekte der CUDA-Architektur vorgestellt und erklärt
zu - Es wird gesagt, dass CUDA-Programmiermodell der SPMD-Programmiermodells sehr ähnelt und es wird ein Vergleich mit weiteren Implementierungen des Modells gemacht
zu
- Die Autoren zeigen die Restriktionen, die für die Cuda-Architektur gelten.
zu - Es werden drei Code-Beispiele vorgestellt, die Lösung der Standart-Probleme zeigen
zu - Autoren versuchen zu belegen, dass CUDA das parallele Programmierung entscheidend erleichtert und es ermöglicht Programme zu schreiben, die Hardware unabhängig arbeiten können.
- Diese Frage wird durch den fachlichen Teil des Artikels beschrieben.
- Tesla-Architketur wird im fachlichen Teil des Artikels beschrieben
Reflect:
Leider werden die Probleme nicht angesprochen. z.B dass es schwer ist, den CUDA-Code zu debuggen oder zu profilen, da es direkt auf der Grafikkarte läuft.
Oder dass nicht alle Algorithmen sich effizient auf die Tesla-Architektur abbilden lassen und sind deswegen unter Umständen deutlich langsamer, als die CPU-Implementation.
Des weiteren wird außer Acht gelassen, dass es sehr viel Zeit kostet ein Programm für die CUDA-Architektur zu optimieren, bzw. wie schwierig es ist.
Recite:
CUDA bietet die Möglichkeit skalierbare parallele Programme ganz einfach zu erstellen. Dem Programmierer wird die aufwändige Verwaltung der Parallelisierung abgenommen. Er braucht nur den seriellen Part auszuprogrammieren und Laufzeitparameter festlegen.
Review:
Der Artikel ist gut strukturiert.
Er liefert kompakt eine Einführung über Cuda-Programierung und -Architektur. Es werden wie Laien so auch Fachleute angesprochen. Technische und nicht-technische Teile sind klar voneinander getrennt.
Es werden verwandte Projekte genannt.
Dieser Artikel ist vertrauenswürdig, da es in einem wissenschaftlich renommierten Zeitschrift erschienen. Leider geht es nicht genug in die Tiefe.
Bestimmte Problembereiche der CUDA wurden nicht beleuchtet.
Im Grossen und Ganzen wird dieser Artikel eine sehr große Hilfe, bei der Erstellung der Ausarbeitung, sein, da es einen guten Überblick verschafft.